스케줄러
스케줄러는 API 서버의 감시 메커니즘을 통해 새로 생성될 파드를 기다리고 있다가, 할당된 노드가 없는 새로운 Pod를 노드에 할당하는 일만 한다.
스케줄러는 선택된 노드에 파드를 실행하도록 지시하지 않는다. 단지 스케줄러는 API 서버로 파드 정의를 갱신한다.(어떤 노드에 할당될지)
-> API 서버는 (감시 메커니즘에 의해) kubelet에 파드가 스케줄링된 것을 통보한다.
-> 대상 노드의 Kubelet은 파드가 해당 노드에 스케줄링된 것을 확인하자마자 파드의 컨테이너를 생성하고 실행한다.
컨트롤러
API 서버는 리소스를 etcd에 저장하고 변경 사항을 클라이언트에게 통보하는 것 외에 다른 일을 하지 않는다. 스케줄러는 파드를 노드에 할당만 한다.
그러므로 API 서버로 배포된 리소스에 지정된 대로 시스템을 원하는 상태로 수렴되도록 하는(kubectl apply -f 등의 명령을 통해 내가 원하던대로 리소스 생성/수정/삭제되기 위해서) 다른 활성 구성 요소가 필요하다. 이는 컨트롤러 매니저 안에서 실행되는 컨트롤러에 의해 수행된다.
여러 컨트롤러가 하나의 컨트롤러 매니저 프로세스에서 실행된다. (필요한 경우, 이들 컨트롤러를 별도의 프로세스로 분할해서 각 컨트롤러 맞춤형 구현으로 교체할 수 있다.)
컨트롤러 목록
- Replication Manager(replicationcontroller 리소스의 컨트롤러)
- replicaset, demonset, job controller
- deployment controller
- node controller
- service controller
- endpoint controller
- namespace controller
- ........(이 밖에 생성할 수 있는 거의 모든 리소스에 컨트롤러가 있다.)
컨트롤러 옵션 조회
kubeadm 툴을 이용했을 시, kube-contoller-manager 는 master 노드 kube-system 네임스페이스에서 Pod 로 존재함을 확인할 수 있다.
kubectl get pods -n kube-systemcat /etc/kubernetes/manifests/kube-controller-manager.yamlkubeadm 툴을 사용하지 않았다면, 다음 명령어를 통해 옵션을 볼 수 있다.
cat /etc/systemd/system/kube-controller-manager.service실행 중인 프로세스 목록에서 검색을 통해 확인할 수도 있다.
ps -aux | grep kube-controller-manager
옵션에 --contollers 이 있는데, 여기서 활성화할 컨트롤러를 선택할 수 있다. 기본적으로 모든 컨트롤러가 활성화된다.
컨트롤러 역할과 동작 방식
컨트롤러는 API 서버에서 리소스(deployment, service 등)가 변경되는 것을 감시하고, 각 변경 작업(새로운 오브젝트를 생성하거나 이미 있는 오브젝트의 갱신 혹은 삭제)을 수행한다. 대부분 이러한 작업은 다른 리소스 생성, (오브젝트의 status 등) 감시 중인 리소스 자체를 갱신하는 것이 포함된다.
(리소스는 클러스터에 어떤 것을 실행해야 하는지 기술하는 반면, 컨트롤러는 리소스를 배포함에 따라 실제 작업을 수행하는 활성화된 쿠버네티스 구성 요소다.)
일반적으로 컨트롤러는 실제 상태를 원하는 상태로 조정하고 새로운 상태를 리소스의 status 섹션에 기록한다. 컨트롤러는 감시 메커니즘을 이용해 변경 사항을 통보받지만 모든 이벤트를 놓치지 않고 받는다는 것을 보장하진 않기 때문에, 정기적으로 목록을 가져오는 작업을 수행해 누락된 이벤트가 없는지 확인해야 한다.
예를 들어, Node controller는 Node들의 상태 활성화되어있는지 항상 모니터링한다.
활성화되지 않는 노드가 있다면, 해당 노드를 unreachable 상태로 변화시키고, 그 Node에 할당된 Pod를 다른 Node로 프로비전하고, 새로운 Pod를 할당 못하게 하는 등의 역할을 수행한다.
컨트롤러 매니저 옵션을 통해 몇 초동안 활성화가 되지 않으면 unreachable 상태로 변화시키는지, 몇 초 동안 다시 Node가 정상으로 돌아오기를 기다리는지를 다 설정할 수 있다.
컨트롤러는 서로 직접 대화하지 않는다. 컨트롤러는 다른 컨트롤러가 존재하는지도 모른다. 각 컨트롤러는 API에 연결하고 감시 메커니즘을 통해 컨트롤러가 담당하는 리소스 유형에서 변경이 발생하면 통보해줄 것을 요청한다.
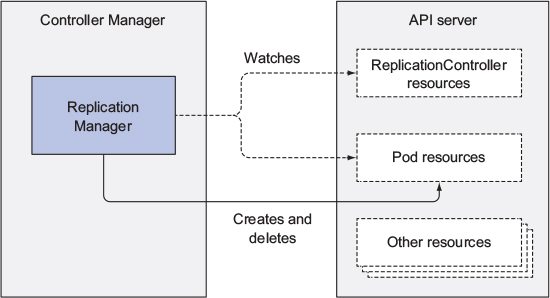

(엔드포인트 컨트롤러: 서비스는 파드에 직접 연결돼 있지 않지만, 서비스에 정의된 파드 셀렉터에 따라 수동 혹은 자동으로 생성되고 갱신되는 엔드포인트(IP와 포트) 목록을 포함한다. 엔드포인트 컨트롤러는 레이블 셀렉터와 일치하는 파드의 IP와 포트로 엔드포인트 리스트를 계속 갱신하는 활성 구성 요소이다.)
위의 그림에서 볼 수 있듯이,
컨트롤러는 감시가 필요한 리소스를 감시 메커니즘을 통해 감시하고, 변화를 수신한다. 변화가 수신될 경우, API 서버로 API 오브젝트(예시로, Replication manager의 경우 Pod resource, API server의 경우 endpoints resources)를 제어한다.(리소스 생성, 갱신 혹은 삭제)
컨트롤러는 그저 API 서버에 리소스를 갱신한다. 컨트롤러는 Kubelet과 직접 통신하거나 어떠한 명령도 내리지 않는다. 사실 컨트롤러는 Kubelet이 존재하는 것조차 알 수 없다.
컨트롤러가 API 서버에 리소스를 갱신하고 난 이후에도 Kubelet과 쿠버네티스 서비스 프록시는 컨트롤러의 존재를 알지 못한 채 파드의 컨테이너에 네트워크 저장소를 붙여 기동하거나 서비스의 경우 파드 사이에 실제로 로드 밸런싱을 설정하는 것과 같은 맡은 일을 수행한다.
예시) 컨트롤러가 새로운 파드 매니페스트를 생성해 API 서버에 게시하면, 스케줄러와 Kubelet이 파드 스케줄링과 실행 작업을 수행한다.
컨트롤러와 스케줄러의 고가용성(HA) 확보
컨트롤러와 스케줄러는 클러스터 상태를 감시하고 상태가 변경될 때 반응해야 하는데, 이런 구성 요소의 여러 인스턴스가 동시에 실행돼 같은 동작을 수행하면, 클러스터의 상태가 예상보다 더 많이 변경될 가능성이 있다. (Pod를 하나 생성해야 하는데, 여러 인스턴스에 동시에 이를 수행함)
이런 이유 때문에 컨트롤러 매니저나 스케줄러 같은 구성요소는 한 번에 하나의 인스턴스만 활성화되어야 한다.
이는 각 개별 구성 요소가 선출된 리더일때만 활성화되는 방식으로 자체적으로 제어된다. 리더만 실제로 작업을 수행하고, 나머지는 대기한다.
리더가 실패할 경우, 나머지 인스턴스 중에서 새로운 리더를 선출하고 기존 작업을 계속 이어서 수행한다. 이 메커니즘을 통해 두 개 이상의 구성요소가 동시에 같은 작업을 수행할 수 없도록 방지한다 .


리더 선출을 위해 endpoint 리소스가 사용된다고 한다.(리더 선출을 위해 남용되는 것..)
아래는 스케줄러의 리더 선출을 위해 endpoint 리소스가 사용되는 예시이다. 모든 스케줄러 인스턴스는 kube-scheduler 엔드포인트 리소스를 생성(나중에는 갱신)하려고 시도한다.
$ kubectl get endpoints kube-scheduler -n kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":
➥ "minikube","leaseDurationSeconds":15,"acquireTime":
➥ "2017-05-27T18:54:53Z","renewTime":"2017-05-28T13:07:49Z",
➥ "leaderTransitions":0}'
creationTimestamp: 2017-05-27T18:54:53Z
name: kube-scheduler
namespace: kube-system
resourceVersion: "654059"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-scheduler
uid: f847bd14-430d-11e7-9720-080027f8fa4e
subsets: []위의 control-plane.alpha.kubernetes.io/leader 어노테이션 부분에 현재 리더의 이름을 가지고 있는 holderIdentity 필드가 있다. 이 이름을 해당 필드에 넣는데 처음 성공한 인스턴스가 리더가 된다.
리더가 되면 주기적으로 리소스를 갱신해서(기본값 2초), 다른 모든 인스턴스에서 리더가 살아 있음을 알 수 있도록 해야 한다. 리더에 장애가 있으면 다른 인스턴스는 한동안 갱신되지 않는 것을 확인하고, 자신의 이름을 리소스에 기록해 리더가 되려고 시도한다.
참고)
쿠버네티스 인 액션(마르코 룩샤) 11장
'개발자: 지식 정리 > 쿠버네티스' 카테고리의 다른 글
| 쿠버네티스 - 컨피그맵 (0) | 2023.01.15 |
|---|---|
| 쿠버네티스 클러스터 구성 요소 및 동작 이해 (4) - Kubelet (0) | 2023.01.15 |
| 쿠버네티스 클러스터 구성 요소 및 동작 이해 (2) - API 서버 (0) | 2023.01.15 |
| 쿠버네티스 클러스터 구성 요소 및 동작 이해 - (1) etcd (0) | 2023.01.15 |
| 쿠버네티스 - API 서버 보안 : RBAC (0) | 2022.06.13 |



