카프카의 탄생
카프카는 소셜 네트워크 서비스 링크드인(LinkedIn)에서 서비스를 운영하며 나타난 기술적인 이슈들을 해결하기 위해 처음 탄생했다.

링크드인 사이트는 서비스가 급속도로 성장하며 기하급수적으로 늘어난 데이터를 관리하는데 큰 어려움을 겪었다.
데이터 생성 및 저장에는 데이터를 생성하는 소스 어플리케이션과 데이터가 최종 저장되는 타겟 어플리케이션, 그리고 이들의 연결이 필요하다.
초기에는 링크드인 아키텍처가 복잡하지 않아서 소스 어플리케이션에서 타겟 어플리케이션 End to End 연결 방식으로 소스코드가 작성되었고, 운영에도 큰 어려움이 없었다. 그러나 시간이 지날수록 아키텍처가 거대해지고 소스 어플리케이션과 타겟 어플리케이션 개수가 많아지며 문제가 발생했다.
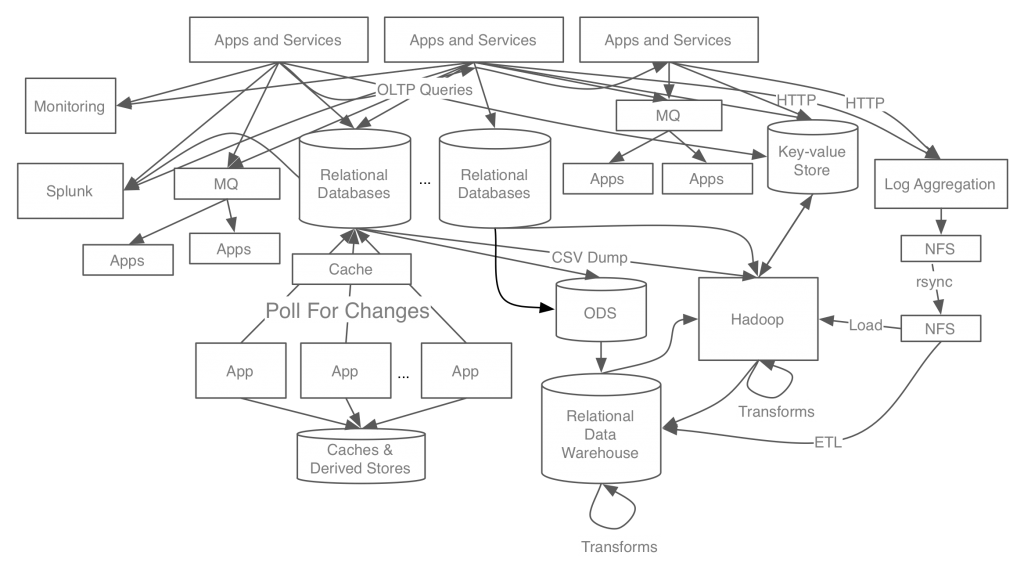
데이터를 전송하는 라인이 많아지며 굉장히 복잡해졌고, 문제가 발생했을 때 조치를 취하기 위해선 여러 시스템에서 확인이 필요했다. 그리고 데이터 전송 라인 별로 데이터 format(형식)과 처리 방법들이 달라 확장이 어렵고 운영이 어려워졌다.
이를 해결하기 위해 링크드인 데이터팀은 신규 시스템을 만들었고, 그 결과물이 아파치 카프카(Apache Kafka)이다.
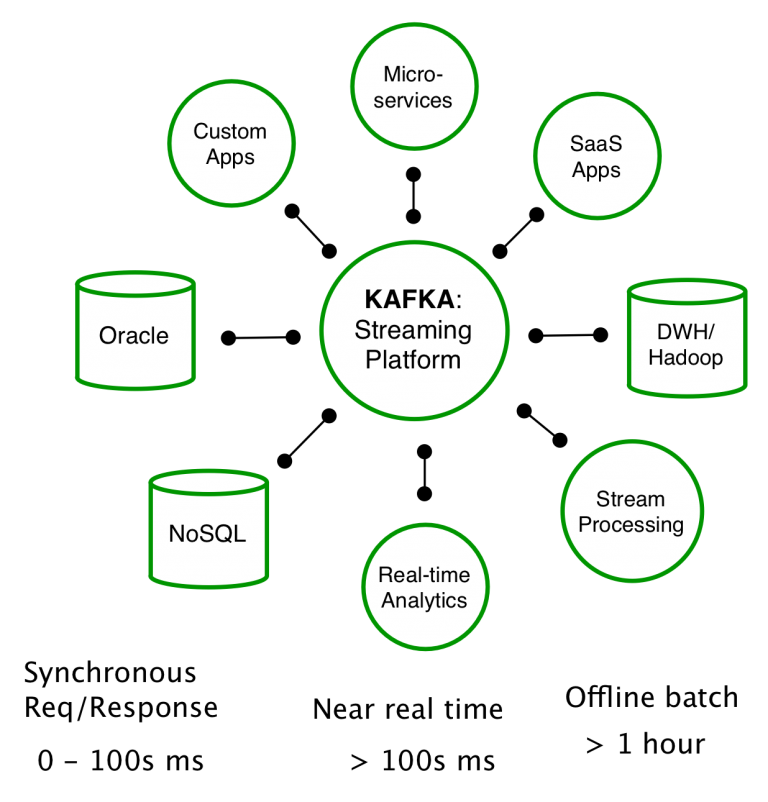
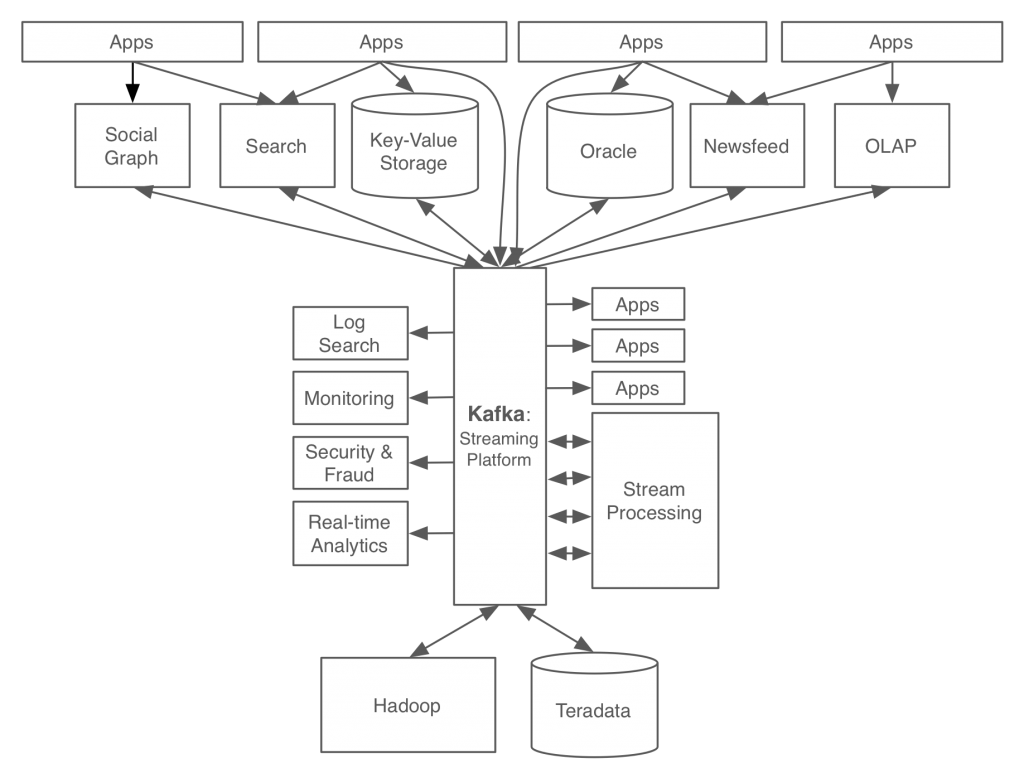
사내에서 발생하는 모든 데이터 흐름을 중앙에서 한곳에 모아 관리하는 카프카를 적용한 결과, 서비스 아키텍쳐가 매우 깔끔해졌다.
카프카에만 데이터를 전달하면 그 데이터가 필요한 다른 서비스들이 데이터를 각자 알아서 가져가는 구조가 되었고, 이로 인해 각 서비스팀에서는 서로 본연의 업무에만 집중할 수 있었다.
참고 문헌 : 카프카, 데이터 플랫폼의 최강자 실시간 비동기 스트리밍 솔루션 Kafka의 기본부터 확장 응용까지