프로세스 개요
프로세스: 실행 중인 프로세스
프로그램은 실행되기 전까지는 그저 보조기억장치에 있는 데이터 덩어리일 뿐…..
보조기억장치에 저장된 프로그램을 메모리에 적재하고 실행하는 순간 그 프로그램은 프로세스가 된다.
프로세스 직접 확인하기
윈도우에서는 작업 관리자의 [프로세스 탭]에서 확인 가능.
유닉스 체계에서 운영체제에ㄴ서는 ps 명령어로 확인이 가능하다.
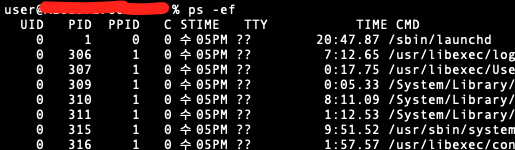
확인해보면 내가 실행한 프로세스 외에도 여러 프로세스가 실행되고 있음을 볼 수 있다.
내가 실행한 프로세스는 포그라운드 프로세스, 나도 모르게 뒤에서 실행되고 있는 프로세스는 백그라운드 프로세스라고 한다. 백그라운드 프로세스를 유닉스 체계의 운영체제에서는 데몬, 윈도우에서는 서비스이라고 부르기도 한다.
프로세스 제어 블록
모든 프로세스는 실행을 위해 CPU를 필요로 한다. 하지만 CPU 자원은 한정되어 있기 때문에(동시에 모두가 쓸 수 없음) 프로세스는 차례대로 돌아가며 한정된 시간만큼만 CPU를 사용한다.
운영체제는 빠르게 번갈아 수행되는 프로세스의 실행 순서를 관리하고, 프로세스에 CPU를 비롯한 지원을 배분한다.
이를 위해 운영체제는 프로세스 제어 블록(PCB) 를 이용한다.
프로세스 제어 블록은 프로세스와 관련된 정보를 저장하는 자료구조이다. 9장에서 봤듯 메모리는 커널 영역과 사용자 영역으로 나눠져있는데, PCB는 커널 영역에 생성된다.
PCB에 담기는 정보는 다음과 같다.
- 프로세스 ID (PID)
프로세스를 식별하기 위해 부여하는 고유한 번호이다. 같은 프로그램을 두 번 실행하더라도 PID가 다른 두 개의 프로세스가 생성된다. - 레지스터 값
프로세스는 자신의 실행 차례가 돌아오면 이전에 사용했던 레지스터들의 값들을 모두 복원한다. 그래야 이전에 진행했던 작업을 그대로 이어 진행할 수 있기 떄문에다. 그래서 PCB안에는 프로세스가 실행하며 사용했던 PC를 비롯한 레지스터 값들이 담긴다. - 프로세스 상태
현재 프로세스가 입출력을 사용하기 위해 기다리는 상태인지, CPU 사용을 기다리고 있는지, CPU 사용을 하는 상태인지 등의 상태 정보 - 스케줄링 정보
프로세스가 언제, 어떤 순서로 CPU를 할당받는지 - 메모리 관리 정보
프로세스가 메모리 어떤 위치에 저장되어 있는지.(페이지 테이블 정보) - 사용한 파일과 입출력장치 목록
프로세스가 실행과정에서 사용한 파일과 입출력장치 목록
컨텍스트 스위칭
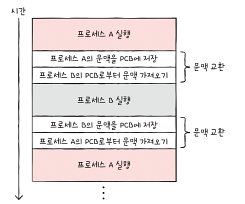
컨텍스트: 프로세스가 (재)실행을 하기 위해 기억해야 할 정보. 실행되다가 다른 프로세스에게 실행 순서를 넘겨야 하는 상황에서 프로세스는 프로그램 카운터를 비롯한 각종 레지스터 값, 메모리 정보, 실행을 위해 열었던 파일이나 사용한 입출력장치 등의 정보를 백업해놔야 한다. 그래야 다음 차례가 왔을 때 이전에 실행했던 내용에 이어서 다시 실행을 재개할 수 있기 떄문이다. 이 정보들, 즉 컨텍스트는 PCB에 기록된다.
컨텍스트 스위칭: 기존 실행되던 프로세스의 컨텍스트를 PCB에 백업하고, 새로운 프로세스를 실행하기 위해 해당 프로세스의 컨텍스트를 PCB로부터 북구하여 새로운 프로세스를 실행하는 것. 이것이 빠르게 일어나면서 우리 눈에는 프로세스가 동시에 실행되는 것처럼 보인다.
프로세스의 메모리 영역
아까봤던 PCB는 메모리에서 커널 영역에 저장된다. 메모리의 사용자 영역에서 프로세스들은 어떤 내용들이 배치될까?
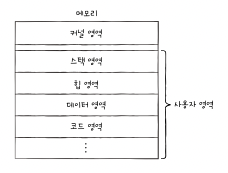
코드 영역
코드, 즉 기계어로 이루어진 명령어가 저장된다.
코드 영역에는 데이터가 아닌 CPU가 실행할 명령어가 담겨있기 때문에 쓰기가 금지되어 있다. 읽기 전용이다.
데이터 영역
프로그램이 실행되는 동안 계속 유지되는 데이터.
ex. 전역 변수
힙 영역
프로그래머가 직접 할당할 수 있는 공간. 힙 영역에 메모리 공간을 할당했다면 언젠가는 해당 공간을 반환해야 한다. 안 해주면 메모리 누수(memory leak)이 나온다.
C 언어에서는 직접 메모리 할당 해제를 해야하지만, JAVA, Javascript, python 등에서는 가비지 컬렉터라는 것이 있어 자동으로 해준다.
스택영역
데이터를 일시적으로 저장하는 공간.
ex. 함수의 실행이 끝나면 사라지는 매개 변수, 지역 변수.
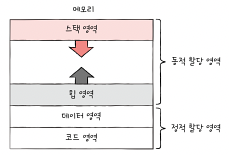
코드 영역과 데이터 영역은 그 크기가 변하지 않는다.(프로그램을 구성하는 명령어들이 안변함(코드 영역 그대로), 데이터 영역에 저장되는 데이터는 프로그램이 실행되는 동안에는 유지되는 데이터(데이터 영역 그대로)).
그래서 정적 할당 영역이라고 한다.
반대로 힙 영역과 스택 영역은 프로세스 실행 과정에서 그 크기가 변할 수 있어서 동적 할당 영역이라고 한다.
프로세스 상태와 계층 구조
프로세스는 모두 저마다의 상태가 있고, 운영체제는 이런 프로세스의 상태를 PCB에 기록하여 관리한다. 그리고 동시에 실행되고 있는 많은 프로세스를 계층적으로 관리한다.
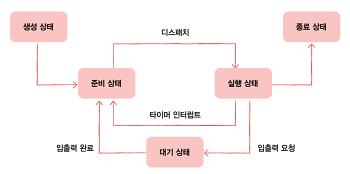
프로세스 상태
보통 컴퓨터를 사용하게 되면, 여러 프로세스들이 빠르게 번갈아가며 실행된다. 이걸 관리하기 위해서 운영체제는 프로세스의 상태를 PCB를 통해 인식하고 관리한다. 보통 관리하는 프로세스 상태가 아래와 같다고 한다.
생성 상태
프로세스를 생성 중인 상태. 이제 막 메로리에 적재되어 PCB를 할당받음.
생성 상태를 거쳐 실행할 준비가 완료된 프로세스는 곧바로 실행되지 않고 준비 상태가 되어 CPU의 할당을 기다림.
준비 상태
당장이라도 CPU를 할당받아 실행할 수 있지만, 차례를 기다리는 상태
실행 상태
CPU를 할당받아 실행 중인 상태. 할당된 일정 시간동안만 CPU를 사용할 수 있음. 프로세스가 할당된 시간을 모두 사용한다면, 다시 준비 상태가 되고, 실행 도중 입출력장치를 사용하여 입출력 장치의 끝날 때까지 기다려야 한다면 대기 상태가 된다.
대기 상태
입출력 작업은 CPU 에 비해 실행 속도가 느림. 입출력 작업을 요청한 프로세스는 입출력 장치가 입출력을 끝낼 때까지(입출력 완료 인터럽트를 받을 때까지) 기다려야 함. 이렇게 입출력 작업을 기다리는 상태를 대기 상태라고 함.
입출력 작업이 완료되면 해당 프로세스는 다시 준비 상태로 CPU 할당을 기다림.
종료 상태
프로세스 종료. 운영체제는 PCB와 프로세스가 사용한 메모리를 정리함.
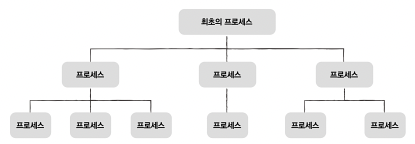
프로세스 계층 구조
프로세스는 실행 도중 시스템 호출을 통해 다른 프로세스를 생성할 수 있다. 이 떄 새 프로세스를 생성한 프로세스를 부모 프로세스(parent process), 생성된 프로세스를 자식 프로세스(child process)라고 한다.
그래도 엄연히 다른 프로세스이기에 각기 다른 PID를 가짐. 일부 운영체제에서는 자식 프로세스의 PCB에 부모 프로세스의 PID인 PPID(parent PID) 를 기록한다.
아래 페이지 참고하자.
https://github.com/kangtegong/self-learning-cs/blob/main/process/process_python.md
참고) 컴퓨터가 구동되면 가장 먼저 생성되는 프로세스, 모든 프로세스 가장 위(모든 프로세스의 조상)에 있는 프로세스는 무엇일까??? 유닉스 프로세스에서는 init, 리눅스에서는 systemd, macOS에서는 launcd라고 한다. 최초의 프로세스 PID는 항상 1번 이다. `pstree` 명령어로 한번 확인해보자
프로세스 생성 기법
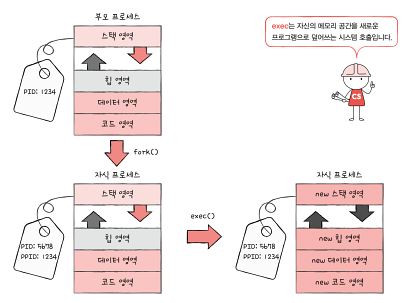
부모 프로세스는 어떻게 자식 프로세스를 만들고, 자식 프로세스는 어떻게 자신만의 코드를 실행할까?
fork, exec 명령어를 통해 가능하다.
fork, exec 는 시스템 호출이다.
부모 프로세스는 fork 시스템 콜을 통해 자신의 복사본을 자식 프로세스로 생성한다. 즉 자기 자신 프로세스의 복제본을 만든다.fork 를 통해 복사본을 만들어진 뒤에 자식 프로세스는 exec 시스템 콜을 통해 새로운 프로그램으로 전환된다. 메모리 공간에 새로운 프로그램 내용이 덮여 써지는 것이다. exec을 호출하면 코드 영역과 데이터 영역의 내용이 실행할 프로그램의 내용으로 바뀌고, 나머지 영역은 초기화됩니다.
이런 방법으로 우리가 보는 모든 프로세스들이 생성되는 것이다!(최초의 프로세스 아래로 가지 뻗치듯)
⭐️스레드⭐️
스레드는 프로세스를 구성하는 실행 흐름 단위이다.
하나의 프로세스는 여러 개의 스레드를 가질 수 있고, 스레드를 이용하면 하나의 프로세스에서 여러 부분을 동시에 실행할 수 있다.
내가 그동안 개인적으로 제일 헷갈렸던게 멀티 코어와 멀티 스레드 멀티 프로세스 이거의 상관관계이다.
(싱글 스레드를 가지면 멀티코어 cpu가 필요없을 거다. 싱글 스레드를 가지는 프로세스 여러개가 있다면 마찬가지로 멀티 코어 제대로 활용 못하는 것 아닌지 등)
이게 무슨 뜬 구름 잡는 소리인지 알아보자.
프로세스와 스레드
전통적으로 하나의 프로세스는 한 번에 하나의 일만 처리했단. 실행의 흐름 단위가 하나라는 점에서, 이런 프로세스들은 단일 스레드 프로세스라고 볼 수 있다.
하지만 스레드라는 개념이 도입되면서 하나의 프로세스가 한 번에 여러 일을 동시에 처리할 수 있게 되었다. 즉, 프로세스를 구성하는 여러 명령어를 동시에 실행할 수 있게 된 것이다. 이게 뭔 말인지 자세히 알아보자면 다음과 같다.
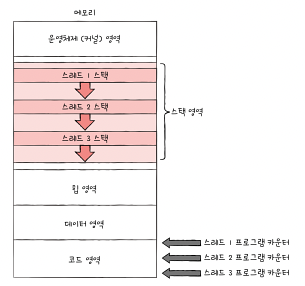
스레드는 프로세스 내에서 각기 다른 스레드 ID, 프로그램 카운터를 비롯한 레시스터 값, 스택으로 구성된다. 각자 프로그램 카운터를 비롯한 레지스터 값, 스택을 가지고 있기에 스레드마다 각기 다른 코드를 실행할 수 있다.
여기서 중요한 점은 프로세스의 스레드들은 실행에 필요한 최소한의 정보(프로그램 카운터를 포함한 레지스터, 스택)만을 유지한 채 프로세스 자원을 공유하며 실행된다는 점이다. 즉 스레드는 프로세스의 자원을 공유한다.
정리하면, 프로세스가 실행되는 프로그램 이라면 스레드는 프로세스를 구성하는 실행의 흐름 단위이다
실제로 많은 운영체제는 CPU에 처리되는 작업을 전달할 때 프로세스가 아닌 스레드 단위로 전달한다 .
그리고 스레드는 프로세스 자원을 공유한 채 실행에 필요한 최소한의 정보만으로 실행된다.
프로세스와 스레드를 구분하는 운영체제도 있고, 명확한 구분을 짓지 않는 운영체제도 있다. 대표적으로 리눅스가 그렇다. 리눅스는 프로세스와 스레드 모두 실행의 문맥(context of execution)이라고 점에서 동등하다고 간주하고 이 둘을 크게 구분 짓지 않는다. 심지어 프로세스와 스레드라는 말 대신 **task** 이라는 이름으로 통일하여 부른다.
멀티프로세스와 멀티 스레드
말그대로 여러 프로세스를 동시에 실행하는 것이 멀티 프로세스,
여러 스레드로 프로세스를 동시에 실행하는 것을 멀티 스레드
단일 프로세스 여러 개 vs 하나의 프로세를 여러 스레드로 실행
차이는 프로세스끼리는 기본적으로 자원을 공유하지 않지만, 스레드끼리는 같은 프로스세 내의 자원을 공유한다는 점!
프로세스를 fork 하여 같은 작업을 하는 동일한 프로세스 2개를 실행하면, 코드 영역, 데이터 영역, 힙 영역 등을 비롯한 모든 자원이 복제되어 메모리에 적재된다. 결과적으로 같은 프로그램을 실행하기 위해 동일한 내용이 중복해서 존재하는 건데 어찌보면 낭비다.
이에 반해 스레드는 각기 다른 스레드 ID, 프로그램 카운터를 포함한 레시시터 값, 스택만 가지고 나머지는 모두 공유한다. 즉, 같은 프로세스 내의 모든 스레드는 동일한 주소 공간의 코드, 데이터, 힙 영역을 공유하고, 열린 파일과 같은 프로세스 자우너을 공유한다. 이로써 메모리를 더 효율적으로 사용할 수 있다.
또한 서로 다른 프로세스들은 기본적으로 자우너을 공유하지 않기 때문에 서로가 독립적으로 실행되는 반면, 스레드는 프로세스의 자원을 공유하기 때문에 서로 협력과 통신에 유리하다
하지만 단점으론 멀티 프로세스에서는 하나의 프로세스에 문제가 생겨도 다른 프로세스에 지장이 없지만, 멀티 스레드 환경에서는 하나의 스레드에 문제가 생기면 프로세스 전체에 문제가 생긴다.
IPC: 프로세스 간 통신 통신이라고 하면 네트워크를 통해 데이터를 주고 받는 방식만을 떠올리기 쉽지만, 같은 컴퓨터 내의 서로 다른 프로세스나 스레드끼리 데이터를 주고받는 것도 통신으로 간주한다. 가령 프로세스 A가 'hello.txt' 파일에 뭔가를 쓰고, 프로세스 B가 'hello.txt'파일에 데이터를 읽으면 두 프로세스 간의 통신이 이루어진 것이다. 이를 파일을 통한 프로세스 간 통신으로 볼 수 있다. 또는 프로세스들이 서로 공유하는 메모리 영역(공유 메모리)을 두어 데이터를 주고 받을 수 있다. 이 외에도 소켓, 파이프 등을 통해 통신을 할 수 있다. 하고 싶은 말은 프로세스들의 통신이 까다로운 것이지 불가능 한 것은 아니다!
'자기계발 > 책' 카테고리의 다른 글
| [🧑🏻💻혼자 공부하는 컴퓨터 구조+운영체제] 14~15장(가상 메모리, 파일 시스템) (0) | 2023.04.16 |
|---|---|
| [🧑🏻💻혼자 공부하는 컴퓨터 구조+운영체제] 11~13장(CPU스케줄링, 동기화, 교착상태) (0) | 2023.04.09 |
| [🧑🏻💻혼자 공부하는 컴퓨터 구조+운영체제] 9장(운영체제란?) 요약 정리 (0) | 2023.03.30 |
| [🧑🏻💻혼자 공부하는 컴퓨터 구조+운영체제] 6~8장(메모리, 보조기억장치, 입출력장치) 요약 정리 (0) | 2023.01.24 |
| [🧑🏻💻혼자 공부하는 컴퓨터 구조+운영체제] 4~5장(CPU 작동 원리) 요약 정리 (0) | 2023.01.24 |

